|
|
||
|---|---|---|
| .. | ||
| configs | ||
| datasets | ||
| doc | ||
| loss | ||
| models | ||
| utils | ||
| vis | ||
| .gitignore | ||
| COAT_pt171.yml | ||
| README.md | ||
| defaults.py | ||
| engine.py | ||
| eval_func.py | ||
| train.py | ||
README.md
COAT代码使用说明
这个存储库托管了论文的源代码:[CVPR 2022] Cascade Transformers for End-to-End Person Search。在这项工作中,我们开发了一种新颖的级联遮挡感知Transformer(COAT)模型,用于端到端的人物搜索。COAT模型在PRW基准数据集上以显著的优势胜过了最先进的方法,并在CUHK-SYSU数据集上取得了最先进的性能。
| 数据集(Datasets) | mAP | Top-1 | Model |
|---|---|---|---|
| CUHK-SYSU | 94.2 | 94.7 | model |
| PRW | 53.3 | 87.4 | model |
Abstract: The goal of person search is to localize a target person from a gallery set of scene images, which is extremely challenging due to large scale variations, pose/viewpoint changes, and occlusions. In this paper, we propose the Cascade Occluded Attention Transformer (COAT) for end-to-end person search. Specifically, our three-stage cascade design focuses on detecting people at the first stage, then progressively refines the representation for person detection and re-identification simultaneously at the following stages. The occluded attention transformer at each stage applies tighter intersection over union thresholds, forcing the network to learn coarse-to-fine pose/scale invariant features. Meanwhile, we calculate the occluded attention across instances in a mini-batch to differentiate tokens from other people or the background. In this way, we simulate the effect of other objects occluding a person of interest at the token-level. Through comprehensive experiments, we demonstrate the benefits of our method by achieving state-of-the-art performance on two benchmark datasets.
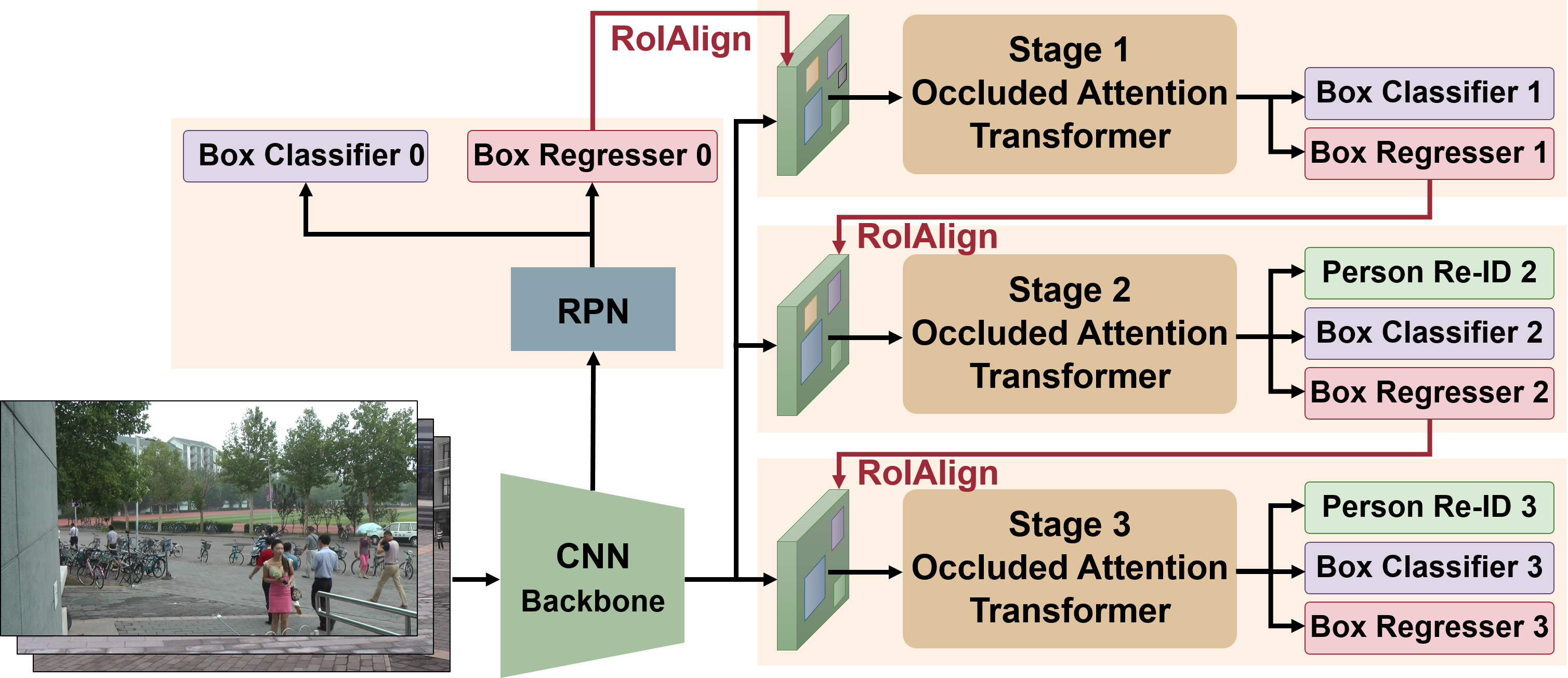
Installation
- Download the datasets in your path
$DATA_DIR. Change the dataset paths in L4 in cuhk_sysu.yaml and prw.yaml.
PRW:
cd $DATA_DIR
pip install gdown
gdown https://drive.google.com/uc?id=0B6tjyrV1YrHeYnlhNnhEYTh5MUU
unzip PRW-v16.04.20.zip
mv PRW-v16.04.20 PRW
CUHK-SYSU:
cd $DATA_DIR
gdown https://drive.google.com/uc?id=1z3LsFrJTUeEX3-XjSEJMOBrslxD2T5af
tar -xzvf cuhk_sysu.tar.gz
mv cuhk_sysu CUHK-SYSU
- Our method is tested with PyTorch 1.7.1. You can install the required packages by anaconda/miniconda with the following commands:
cd COAT
conda env create -f COAT_pt171.yml
conda activate coat
If you want to install another version of PyTorch, you can modify the versions in coat_pt171.yml. Just make sure the dependencies have the appropriate version.
CUHK-SYSU数据集实验
训练: 目前代码只支持单GPU. The default training script for CUHK-SYSU is as follows:
在本地GTX4090训练:
cd COAT
# 说明:4090显存较小,所以batchsize只能设置为2, 实测可以运行
python train.py --cfg configs/cuhk_sysu-local.yaml INPUT.BATCH_SIZE_TRAIN 2 SOLVER.BASE_LR 0.003 SOLVER.MAX_EPOCHS 14 SOLVER.LR_DECAY_MILESTONES [11] MODEL.LOSS.USE_SOFTMAX True SOLVER.LW_RCNN_SOFTMAX_2ND 0.1 SOLVER.LW_RCNN_SOFTMAX_3RD 0.1 OUTPUT_DIR ./logs/cuhk-sysu
在本地UESTC训练:
cd COAT
# 说明:RTX8000显存48G,所以batchsize只能设置为3
python train.py --cfg configs/cuhk_sysu.yaml INPUT.BATCH_SIZE_TRAIN 2 SOLVER.BASE_LR 0.003 SOLVER.MAX_EPOCHS 14 SOLVER.LR_DECAY_MILESTONES [11] MODEL.LOSS.USE_SOFTMAX True SOLVER.LW_RCNN_SOFTMAX_2ND 0.1 SOLVER.LW_RCNN_SOFTMAX_3RD 0.1 OUTPUT_DIR ./logs/cuhk-sysu
Note that the dataset-specific parameters are defined in configs/cuhk_sysu.yaml. When the batch size (INPUT.BATCH_SIZE_TRAIN) is 3, the training will take about 23GB GPU memory, being suitable for GPUs like RTX6000. When the batch size is 5, the training will take about 38GB GPU memory, being able to run on A100 GPU. The larger batch size usually results in better performance on CUHK-SYSU.
For the CUHK-SYSU dataset, we use a relative low weight for softmax loss (SOLVER.LW_RCNN_SOFTMAX_2ND 0.1 and SOLVER.LW_RCNN_SOFTMAX_3RD 0.1). The trained models and TF logs will be saved in the folder OUTPUT_DIR. Other important training parameters can be found in the file COAT/defaults.py. For example, CKPT_PERIOD is the frequency of saving a checkpoint model.
Testing: The test script is very simple. You just need to add the flag --eval and provide the folder --ckpt where the model was saved.
测试:这个测试脚本非常简单,你只需要添加flag --eval以及对应提供--ckpt当模型已经保存的时候
python train.py --cfg ./configs/cuhk-sysu/config.yaml --eval --ckpt ./logs/cuhk-sysu/cuhk_COAT.pth
Testing with CBGM: Context Bipartite Graph Matching (CBGM) is an optimized matching algorithm in test phase. The detail can be found in the paper [AAAI 2021] Sequential End-to-end Network for Efficient Person Search. We can use CBGM to further improve the person search accuracy. In test script, we just set the flag EVAL_USE_CBGM to True (default is False).
python train.py --cfg ./configs/cuhk-sysu/config.yaml --eval --ckpt ./logs/cuhk-sysu/cuhk_COAT.pth EVAL_USE_CB GM True
Testing with different gallery sizes on CUHK-SYSU: The default gallery size for evaluating CUHK-SYSU is 100. If you want to test with other pre-defined gallery sizes (50, 100, 500, 1000, 2000, 4000) for drawing the CUHK-SYSU gallery size curve, please set the parameter EVAL_GALLERY_SIZE with a gallery size.
python train.py --cfg ./configs/cuhk-sysu/config.yaml --eval --ckpt ./logs/cuhk-sysu/cuhk_COAT.pth EVAL_GALLER Y_SIZE 500
Experiments on PRW
Training: The script is similar to CUHK-SYSU. The code currently only supports single GPU. The default training script for PRW is as follows:
在本地GTX4090训练:
cd COAT
# PRW数据集较小,可以RTX4090的bs可以设置为3
python train.py --cfg ./configs/prw-local.yaml INPUT.BATCH_SIZE_TRAIN 3 SOLVER.BASE_LR 0.003 SOLVER.MAX_EPOCHS 13 MODEL.LOSS.USE_SOFTMAX True OUTPUT_DIR ./logs/prw
在本地UESTC训练:
cd COAT
# PRW数据集较小,可以RTX4090的bs可以设置为3
python train.py --cfg ./configs/prw.yaml INPUT.BATCH_SIZE_TRAIN 3 SOLVER.BASE_LR 0.003 SOLVER.MAX_EPOCHS 13 MODEL.LOSS.USE_SOFTMAX True OUTPUT_DIR ./logs/prw
The dataset-specific parameters are defined in configs/prw.yaml. When the batch size (INPUT.BATCH_SIZE_TRAIN) is 3, the training will take about 19GB GPU memory, being suitable for GPUs like RTX6000. The larger batch size does not necessarily result in better accuracy on the PRW dataset.
Softmax loss is effective on PRW. The default weights of softmax loss at Stage 2 and Stage 3 (SOLVER.LW_RCNN_SOFTMAX_2ND and SOLVER.LW_RCNN_SOFTMAX_3RD) are 0.5, which can be found in the file COAT/defaults.py. If you want to run a model without Softmax loss for comparison, just set MODEL.LOSS.USE_SOFTMAX to False in the script.
Testing: The test script is similar to CUHK-SYSU. Make sure the path of pre-trained model model is correct.
python train.py --cfg ./logs/prw/config.yaml --eval --ckpt ./logs/prw/prw_COAT.pth
Testing with CBGM: Similar to CUHK-SYSU, set the flag EVAL_USE_CBGM to True (default is False).
python train.py --cfg ./logs/prw/config.yaml --eval --ckpt ./logs/prw/prw_COAT.pth EVAL_USE_CBGM True
Acknowledgement
This code borrows from SeqNet, TransReID, and DSTT.
Citation
If you use this code in your research, please cite this project as follows:
@inproceedings{yu2022coat,
title = {Cascade Transformers for End-to-End Person Search},
author = {Rui Yu and
Dawei Du and
Rodney LaLonde and
Daniel Davila and
Christopher Funk and
Anthony Hoogs and
Brian Clipp},
booktitle = {{IEEE} Conference on Computer Vision and Pattern Recognition},
year = {2022}
}
License
This work is distributed under the OSI-approved BSD 3-Clause License.